Defending from Forced Browsing…good reasons not to just hide restricted content
Secure coding to protect against forced browsing. Strong defences from forced browsing require controls such as Role Based Access. Here we explain how to mount a good defence!

(Note: If you'd like a LOT more detail then take a look at my Pluralsight course on Secure Coding: Broken Access Control)
Forced browsing is where a user chooses the locations they browse to instead of allowing the user interface to decide.
A user typically only browses to pages on a website which the website gives them links to. The user will click links and get to the content they expect. But what if that user decides to simply start typing what they like in the address bar of the browser? Are there hidden pages that the website is just hoping will stay hidden?
Worse still, what if there were various methods available to help someone find addresses that you haven’t got links to?
Here we’re going to look at forced browsing, first from the viewpoint of an attacker, then taking a look at how we might defend against it.
What’s the Damage from Forced Browsing?
A quick way to restrict access to web pages and functionality is sometimes to simply not show people links to it. If that is the only restriction in place then it’s only a matter of time before someone who shouldn’t be able to access, does.
If a non-admin user doesn’t see links to admin content, can they still browse to it manually? If they get there can they perform admin functions?
You could consider that security by obscurity, and that’s not a good thing.
The Attack
As an attacker, forced browsing is a means of finding areas they may not be authorised to access. They may be trying to access them as an anonymous user, but are more likely to be trying to do it as an authenticated user. The areas being accessed may check for authentication (i.e. is this person logged in), but may not have further controls for authorisation (i.e. only an admin user should be here). As a result, a user with little access may be able to access more restricted areas, such as admin functionality, simply because they found the correct URL.
There are a number of methods an attacker can use to find endpoints that they shouldn’t be able to access, so let’s take a look at some of the common methods:
Forced Browsing with a Tool
One of the simplest and most effective methods of finding endpoints is to simply use a tool to brute force hundreds or thousands of requests and look for responses that suggest success.
A tool like dirbuster allows you to enter a URL, give it a file with commonly used words and it’ll try to use all of those words in the URL. If you want, it will work recursively, so if one of the words it used in the URL works, it’ll treat that as a likely directory and try the word list again for that directory. You can also try common file types such as .html and .aspx. Additionally you can add HTTP headers, so if you’ve got cookies you were given when you logged in to a session, it will attach those to your requests and it will make requests as if you were logged in using a browser.
Tools such as Burp Suite work in a similar way. The Intruder option in Burp allows you to take a captured request from a browser and use a word list to brute force part of the request.
These options work well, but can be very time consuming and also throws a lot of requests at the server, which might get noticed or even blocked.
Using an Application Against Itself
A more subtle attack is to see if the application itself gives away any of the locations that might be interesting. Web pages often give away lots of information that can be useful:
- Commented code / HTML
- Hidden HTML elements intended only for specific roles
- Javascript code
- Robots.txt
Even if web pages don’t currently give away any useful endpoints, they may have in the past so something like the WaybackMachine might be useful to view historical versions of the website.
Defences
So we’ve seen the ways forced browsing might be used to attack an application, how do we defend against it?
The strongest defence is to correctly apply authorisation when requests for content are made. We’re not just checking that the request is coming from a logged in user, we’re also ensuring that the user is authorised to access the resource. Even if a user manages to find this resource without a link, they can’t use it unless they specifically have access to it. Notably, this check is only effective if it’s performed on the server side.
“Authorisation checks on the client side help with usability, on the server side they help with security.”
Access Control
There are two structured methods to perform these checks. The slightly simpler of the two is Access Control Lists (ACL).
To understand ACLs we first need a quick note on how we define access. A common way to do this is subject-object-action, where:
- Subject – typically the user
- Object – the resource being accessed
- Action – the action being performed on the object
To put an example into English:
User1 (the subject) can create (the action) new users (the object)

This forms the basis of an ACL, which is just a list of access definitions. An ACL typically works at a user level and there will be a number of records for each user. This only really works well for a small number of users where there are unlikely to be many changes. Beyond that, maintenance might get complicated.
The second method is really an extension of an ACL and is a Role Based Access Control (RBAC). Here, the subject is a role instead of a user, so:
The Admin role (the subject) can create (the action) new users (the object)
While this looks essentially the same as an ACL, it importantly has another layer. A user may be assigned the Admin role and that role has permissions instead of the user having its own permissions.

The benefit here is that we can have clearly defined roles: developer, tester, network administrator etc and those roles only have the permissions needed for that job. There may be times when a developer needs to also perform a tester role, so they might temporarily get the additional role of tester and have it removed later. At some point a role might need an additional permission and so it gets added to the role, effectively giving every user with that role the new permission.
Implementing RBAC
We’ve gone over the concept of RBAC, so let’s get some thoughts about implementing it in code.
As we’ve already mentioned, it’s important to perform access controls on the server side, we should assume that anything happening on the client side can be controlled by the client.
The check on the server side should happen at the earliest possible point in our code. There is likely to be a point at which you check a user is authenticated, after that check, we should be able to check for authorisation.
Frameworks like ASP.NET MVC and node.js Express typically have a pipeline associated with HTTP requests, essentially a number of stages that an incoming request goes through before a response is sent. At multiple points in the life cycle of a request, the developer has the opportunity to interact with it.
An example of the ASP.NET pipeline looks something like this:
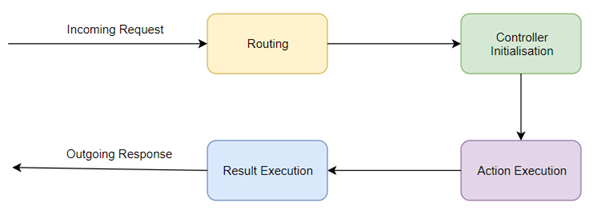
Looking a little closer at the ASP.NET MVC pipeline, specifically the Action Execution stage (Although there will be similar stages in pipelines of other frameworks)
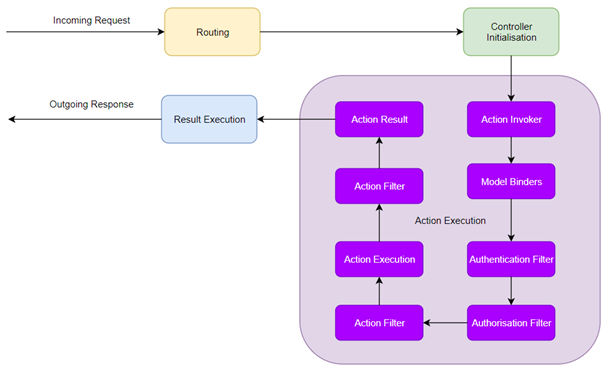
We can see there are specific stages within action execution, including an Authentication Filter and an Authorisation filter.
RBAC is all about authorisation, so we would put our code into the Authorisation Filter. From there we would have the ability to return an error if the user wasn’t authorised to access the resource, or allow the request to continue through the pipeline.
RBAC is a good defence from forced browsing vulnerabilities, clearly you need to implement it on all of your endpoints and make sure it works properly...automated tests anyone?
If you’re not already signed up to Pluralsight then you can get a free 10 day trial here.
Related Links
Got a comment or correction (I’m not perfect) for this post? Please leave a comment below.
Subscribe to Gavin Johnson-Lynn
Get the latest posts delivered right to your inbox